发表于 NIPS 2019
1. Introduction
Four vision-and-language tasks:
- visual question answering
- visual commonsense reasoning
- referring expressions
- capation-based image retrieval
Motivation:
pretrained models can provide useful information for target tasks, e.g. dog breed-sensitive image features or a well-calibrated semantic distance between words.
equally important is how they relate to one another
developing a common model for visual grounding that can learn these connections and leverage
them on a wide array of vision-and-language tasks
A suitable data source where alignment between vision and language is available —— Conceptual Captions dataset
key technical innovation:
introducing separate streams for vision and language processing that communicate through co-attentional transformer layers
Contributions:
- find improvements of 2 to 10 percentage points across these tasks when compared to state-of-the-art task-specific baselines using separately pretrained vision and language models
- our structure is simple to modify for each of these tasks – serving as a common foundation for visual grounding across multiple vision-and-language tasks.
2. Approach
develop a two-stream architecture modelling each modality separately and then fusing them through a small set of attention-based interactions
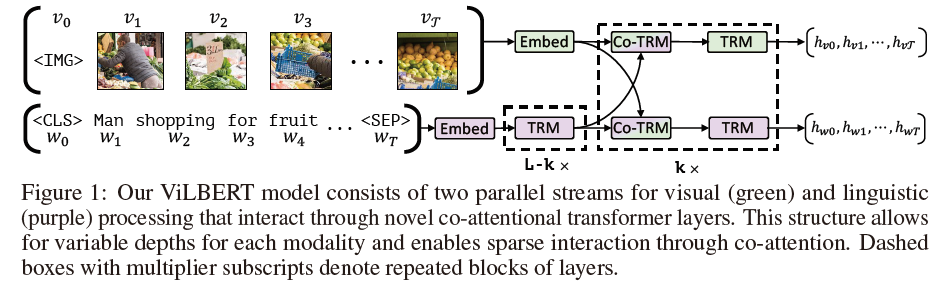
- ViLBERT consists of two parallel BERT-style models operating over image regions and text segments
- each stream is a series of transformer blocks(TRM) and novel co-attentional transformer layers(Co-TRM)
Co-Attentional Transformer Layers
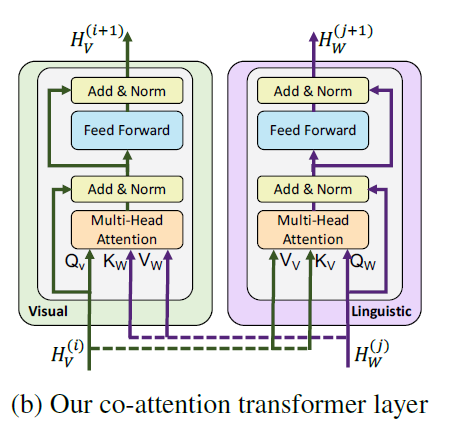
The keys and values from each modality are passed as input to the other modality’s multi-headed attention block
Training Tasks and Objectives
dataset: Conceptual Captions dataset
the masked multi-modal modelling task
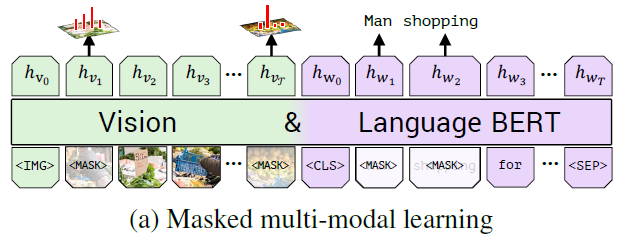
masking approximately 15% of both words and image region inputs and tasking the model with reconstructing them given the remaining inputs.
- predict the words of the masked
- predict a distribution over senmantic classed for the corresponding image region
the multi-modal alignment task
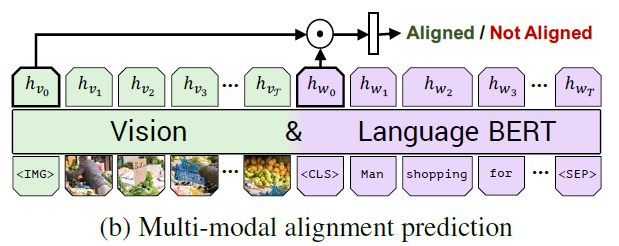
- image-text pair: ${IMG, v_1, …, v_T, CLS, w_1, …, w_T, SEP}$
- predict whether the text describes the image
- the overall representation as an element-wise product between $h_{IMG}$ and $h_{CLS}$ and learn a linear layer to make the binary prediction whether the image and text are aligned
3. Experimental Settings
We select regions where class detection probability exceeds a confidence threshold and keep between 10 to 36 high-scoring boxes
Vision-and-Language Transfer Tasks
transfer our pretrained ViLBERT model to a set of four established vision-and-language tasks
VQA: learn a two layer MLP on top of the element-wise product of the image and text representations $h_{IMG}$ and $h_{CLS} $
treat VQA as a multi-label classification task
VCR: concatenate the question and each possible response to form four different text inputs and pass each through ViLBERT along with the image. We learn a linear layer on top of the post-elementwise product representation to predict a score for each pair.
Grounding Referring Expressions:
- task: localize an image region given a natural language reference
- pass the final representation $h_{v_i}$ for each image region $i$ into a learned linear layer to predict a matching score
Caption-Based Image Retrieval:
- task: identifying an image from a pool given a caption describing its content
- We train in a 4-way multiple-choice setting by randomly sampling three distractors(干扰因素) for each image-caption pair – substituting a random caption, a random image, or a hard negative from among the 100 nearest neighbors of the target image.
- compute the alignment score for each, and the sort