发表于 EMNLP 2019
1. Introduction
- three encoders:
- an object relationship encoder
- a language encoder
- a cross-modality encoder
- pre-train the model with large amounts of image-and-sentence pairs, via five pre-training tasks:
- masked language modeling
- masked object predicition via ROI-feature regression
- masked object predicition via detected-label classification
- cross-modality matching
- image question answering
2. Model Architecture
- two inputs: an image and its related sentence (a caption or a question)
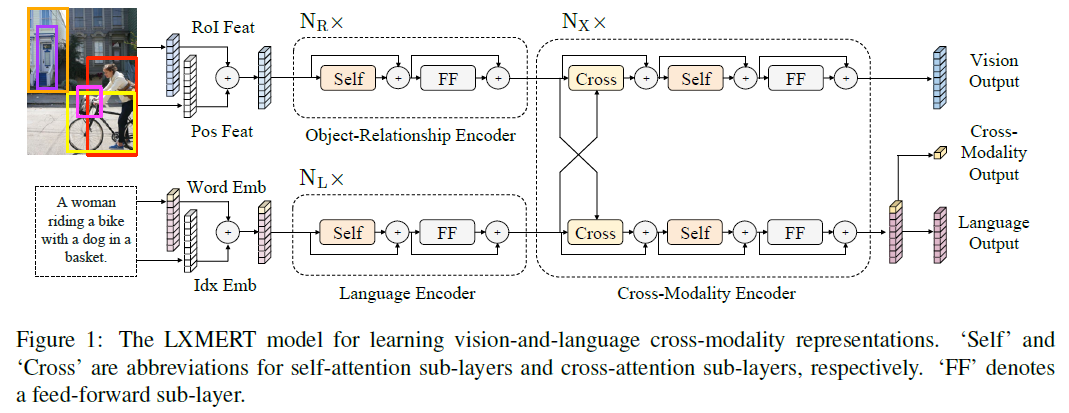
2.1 Input Embeddings
word-level sentence embeddings
$$
sentence = {w_1, …, w_n} \
\hat{w_i} = WordEmbed(w_i) \
\hat{\mu_i} = IdxEmbed(i) \
h_i = LayerNorm(\hat{w_i} + \hat{\mu_i})
$$object-level image embeddings
- m objects: ${o_1, …, o_m}$
- each object $o_j$ is represented by its position feature $p_j$ and its 2048-dimensional RoI feature $f_j$
- learn a position-aware embedding $v_j$ by adding outputs of 2 fully-connected layers
$$
\hat{f_j} = LayerNorm(W_Ff_j + b_F) \
\hat{p_j} = LayerNorm(W_pp_j + b_p) \
v_j = (\hat{f_j} + \hat{p_j}) / 2
$$
2.2 Encoders
single-modality encoders
‘self’ means self-attention sublayers —— query 向量是其本身
feed-forward sub-layer is further composed of two fully-connected sub-layers
‘+’ means residual connection and layer normalization
- Cross-Modality Encoder
- two unidirectional cross-attention sub-layers: one from language to vision and one from vision to language
- exchange the information and align the entities between the two modalities in order to learn joint cross-modality representations
2.3 Output Representations
the outputs:
- the vision output
- the language output
- the cross-modality output : append a special token [CLS] before the sentence words, and the correspinding feature vector of this special token in language feature sequences is used as the cross-modality output