发表于 EMNLP 2019
1. Introduction
模型:Bounding Boxes in Text Transformer (B2T2)
Motivation:
In this paper, we consider visual context in addition to language and show that the right integration
of visual and linguistic information can yield improvements in visual question answering.
视觉信息和语言信息的正确结合可以提升视觉问答的性能。
Question:
- how to encode visual and verbal information in a neural architecture?
- How are text entities bound to objects seen in images?
- Are text and image best integrated late, allowing for independent analysis (late fusion), or should the processing of one be conditioned on the analysis of the other (early fusion)?
- How is cross-modal co-reference best encoded at all?
- Does it make sense to ground words in the visual world before encoding sentence semantics?
Dataset:
Visual Commonsense Reasoning
questions, answers and rationales created by human annotators
Conclusion:
early fusion of co-references between textual tokens and visual features of objects was the most critical factor in obtaining improvements on VCR
在VCR中,早期融合更有效
the more visual object features we included in the model’s input, the better the model performed, even if they were not explicitly co-referent to the text, and that positional features of objects in the image were also helpful
即使视觉特征与文本不是显式相关的,但是加入更多的视觉特征能够提升模型,object 的位置特征也是有帮助的
our models for VCR could be trained much more reliably when they were initialized from pretraining
on Conceptual Captions, public dataset of about 3M images with captions.利用 Conceptual Captions 初始化更有效
2. Problem Formulation
介绍符号
3. Models and Methods
Dual Encoder: a late fusion architecture
image and text are encoded separately and answer scores are computed as an inner product
full B2T2 model: a early fusion architecture
visual features are embedded on the same level as input word tokens
3.1 Dual Encoder
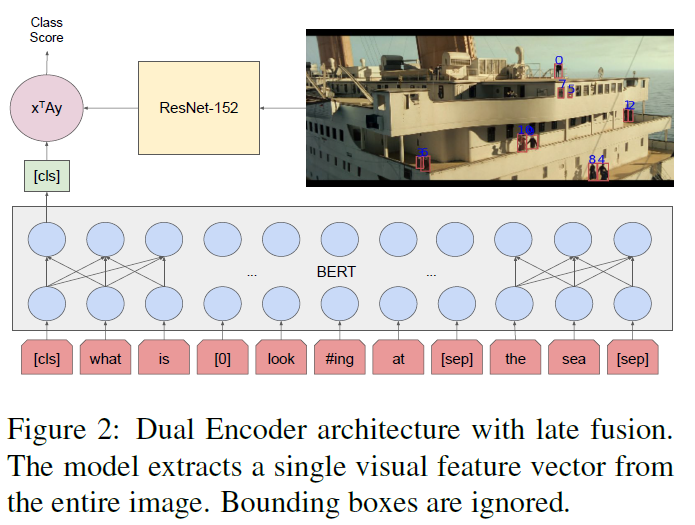
$$
p(l = 1|I, T) = \frac{1}{1 + e^{-\Psi(E(T))^TD\Phi(I)}}
$$
公式的符号从右到左依次为:
$I$:图像
$\Phi$:$R^{w \times h \times 3} \rightarrow R^d$ 抽取图像特征,得到 $d$ 维向量
$D$:learned matrix of size $d \times h$
$T$:$T = [t_1, …, t_n]$, $N^{n \times 2}$, input tokens
$E$:$N^{n \times 2} \rightarrow R^{n \times h}$ , token embeddings
$\Psi$:$R^{n \times h} \rightarrow R^{h}$,[CLS] embedding
3.2 B2T2
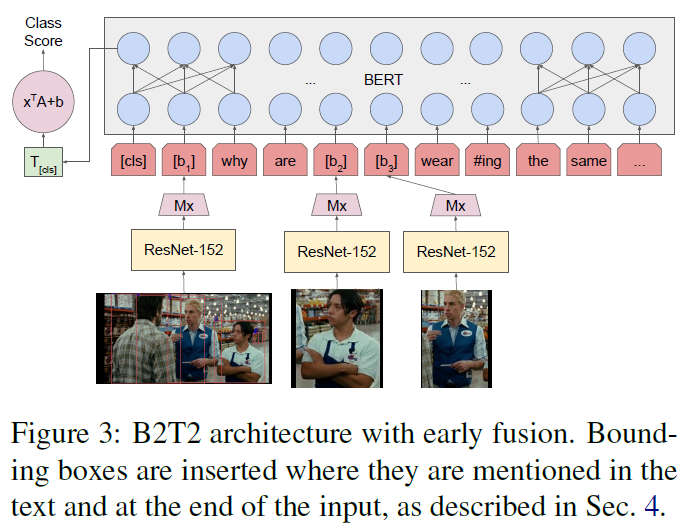
*The key difference from “Dual Encoder”: *
text, image and bounding boxes are combined at the level of the non-contextualized token representations rather than right before the classification decision
$$
p(l | I, B, R, T) = \frac{e^{\Psi(E’(I, B, R, T)) · a_l + b_l}}{\sum_{l’} e^{\Psi(E’(I, B, R, T)) · a_{l’} + b_{l’}}}
$$
$a_l \in R^h$
$b_l \in R$
$E’(I,B,R,T)$ 的计算过程如下图所示。
$$
E’(I, B, R, T) = E(T) + \sum^m_{i = 1} R_i[M(\Phi(crop(I, b_i)) + \pi(b_i))]^T
$$- $R$ : $R \in {0, 1} ^ {m \times n}$ , $R_{ij} = 1$ 当且仅当 bounding box i 与 token j 对应 (该项为数据集给出)
- $M$ : learned $h \times d$ matrix
- $\Phi(crop(I, b_i))$:bounding box $b_i$ 对应的 $d$ 维视觉特征
- $\pi(b_i)$:bounding box 的位置和形状 embedding,也是 $d$ 维
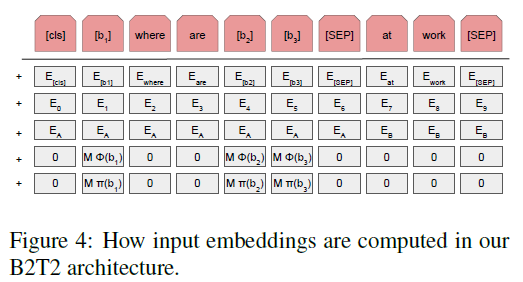
4. Data
该数据集包括 3 个任务:
$Q \rightarrow A$ task
$$
[CLS], [b_0], q_0, …, [SEP], a_0, …, [SEP], l_1, [b_1], …, l_p, [b_p]
$$- $q_0, …$ : 问题
- $a_0, …$:答案
- $l_1$: token 1
- $[b_1]$:对应 $l_1$ 的 bounding box
- $[b_0]$:完整的图像
$QA \rightarrow R$ task
$$
[CLS], [b_0], q_0, …, [SEP], a^*_0, …, r_0, …, [SEP], l_1, [b_1], …, l_p, [b_p]
$$- $a^*_0$: 正确的答案
- $r_0$:线索
注意,这两个任务中,作者均是插入图像中的前 $p$ 个 bounding boxes (这里的 $p$ 作者选用的 8)
对于 Q, A, R 中有对应 bounding box 的 token,作者 prepend the class label token ($[b_i]$ becomes $ l_i, [b_i]$)
- $Q \rightarrow AR$ task
这里作者没有写,由以上两个任务结合吗?