发表于 IEEE FG 2019
(FG = face and gesture recognition)
1. Introduction
介绍前人工作
- siamese deep convolutional network
- Conditional Random Field
definition of social relation
遵照 《Learning Social Relation Traits from Face Images》论文 8 个 binary relation 的划分
spatial cues are explored as auxiliary input to the proposed network
features extracted with deep networks applied on the whole images are used as auxiliary input to the siamese-like network to predict social relation
2. The Proposed Method
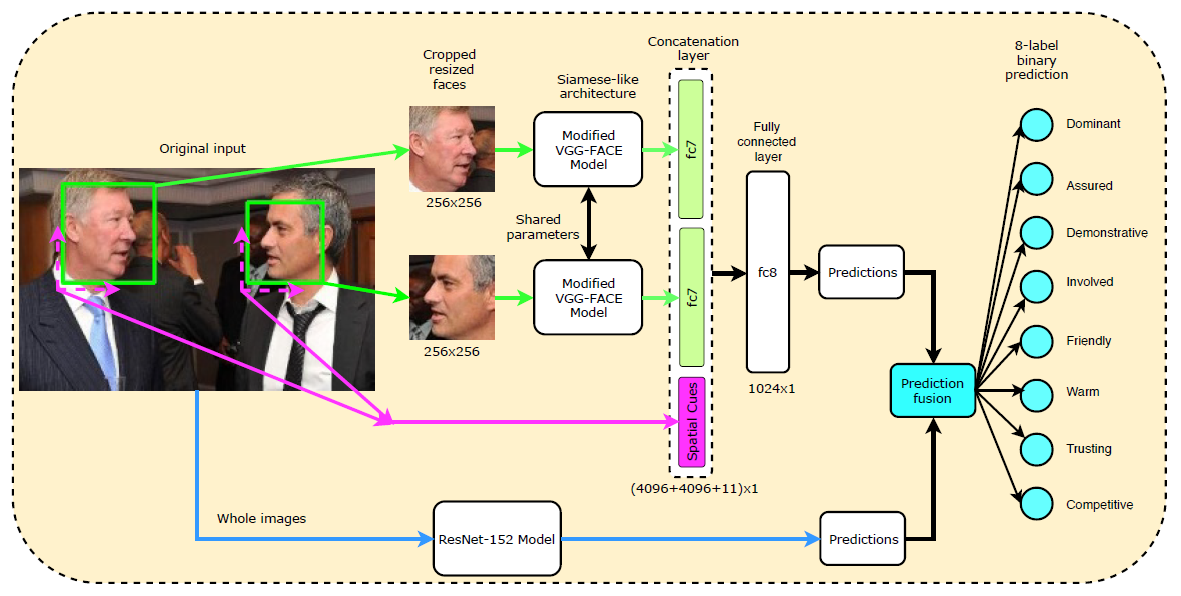
A. Proposed Siamese-like Network
采用 VGG-FACE 模型作为 backbone,经过VGG-FACE得到 4096 维的特征向量
引入了 11 维的 spatial cues,不同的是在 concatenate 到向量前已经进行 normalized。论文解释 normalization 的理由:VGG-FACE 得到的值很小,接近于 0
concatenate 之后的向量,经过全连接层 fc8
An additional fully connected layer fc8 with 1024 hidden neurons is built on top of the concatenated feature vector to learn high-level joint representations
(输入为 4096 * 2 +11 维,得到 1024 维的 high-level joint representations?)
fc8 之后,再经过一层 logistic classifier,求得对于每个 social relation categories,为正例的可能性
(具体可参考逻辑回归分类器详解)
训练细节:
- 前10层卷积层保持与 VGG-FACE model 一致
- 最后三层卷积层及两层全连接层 (fc6 和 fc7) 进行 fine-tune
- 最后一层全连接层 fc8 重新训练(trained from scratch)
B. Deep Models Based on Whole Images
作者认为,可以基于整张图片来预测 relation
Social relationships can still be predicted using proper deep learning networks trained on whole images
采用三种 SOTA 网络结果(基于 ImageNet dataset 的结果)
- VGG
- Inception-v2
- ResNet
最后一层全连接层被替换为 8 个并列的二元输出全连接层
ResNet-152 的实验结果最好
3. Experimental Result
A. Dataset
与第一篇论文的数据集相同,包含从网络和电影中选取的 8016 张图片(train: 7226, test: 790)
每一张图片包括 faces’ bounding boxes 和 multi-labeled with their pairwise relations
B. Evaluation Metric
与 《Learning Social Relation Traits from Face Images》 相同