发表于 ICCV 2017
1. Introduction
- 提出了 dual-glance model
- the first glance fixates at the individual pair of interest
- the second glance exploits contextual cues from regions generated from Region Proposal Network(RPN) to refine the coarse prediction
- 提出了 Attentive RCNN (一种 attention 算法?)
- 构造数据集:PISC dataset,包括 22670 张图片和 76568 个标注标签,9种社交关系
2. People in Social Context Dataset (PISC dataset)
- 从不同的数据集和社交搜索引擎中搜集图片,40k张图片
- 利用 Faster RCNN 检测图片,标注 bounding boxes,再进行人工检查
- 只选择人物占据明显区域的图片
- 每张图片中的图片人物数为 3.11
3. Proposed Dual-Glance Model
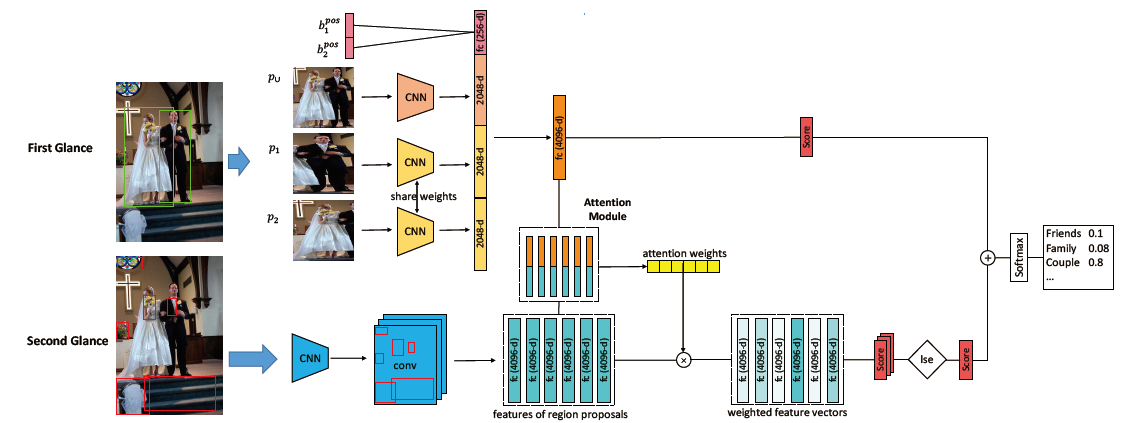
A. First Glance
3 bounding boxes contain $p_1$、$p_2$、$p_{union}$ ,resize 为 224 * 224,经过 CNN 提取特征,特征为 4096 维。$p_1$ 和 $p_2$ 经过的 CNN 权重相同
引入了 10 维的 spatial feature,且经过 normalization
$$
b_i^{pos} = {x^{min}_i, y^{min}_i, x^{max}_i, y^{max}_i, area_i} \
spatial_feature = [b^{pos}_1; b^{pos}_2]
$$concatenate 之后,经过两层全连接层得到 first glance score $S_1$
B. Attentive RCNN for Score Glance
对于每一对 bounding box $b_1$ 和 $b_2$,得到一组上下文区域 $R(b_1, b_2; I)$
$$
R(b_1, b_2; I) = {c \in P_I: max(G(c, b_1), G(c, b_2)) < \tau_{u}}
$$
其中,$G$ 函数表示 $IoU$ 的计算,$\tau_u$ 表示 $IoU$ 的阈值是以,得到了一系列 $b_1$ 和 $b_2$ 之外的 contextual region
对于每一个 contextual region,经过 $ROI \ pooling$ ,得到 4096 维的特征,经过 attention 之后得到 $v^{att}_i$,$v^{att}_i$ 经过一层全连接层得到 $s_i$,最后经过 $log-sum-exp$ 得到 second glance score $S_2$
$$
S_2 = log[1 + \sum^N_{i = 1} exp(s_i)]
$$
4. Experiment
4.1 Dataset and Training Details
经过两个 recognition tasks 作 evaluate:
First Task: 3-relationship recognition —— No Relation, Intimate Relation, Non-Intimate Relation
Second Task: 6-relationship recognition —— Friends, Family, Couple, Professional, Commercial, No Relation
由于不同 relationship 出现的频率不同,采用 oversampling and undersampling strategies
*oversampling: *
- reverse the pair of people ( 如果 a 和 b 是 couple,那么 b 和 a 也是 couple)
- horizontally flipping the image
*undersampling: *
- using stratified sampling scheme to ensure the samples in each batch is balanced
训练细节
- 采用随机梯度下降
- 首先训练 first-glance model
- fine-tune ResNet-101 model pre-trained on ImageNet classification task
- 接着 freeze the first-glance model,训练 second-glance model
- fine-tune the VGG-16 model pretrained on ImageNet detection task
- fine-tuning model has a lower learning rate of 0.0001
- batch size = 32
- momentum = 0.9
4.2 Single-Glance vs. Dual-Glance
- Union-CNN: 基于 Union region 做分类
- BBox:基于 spatial feature 做分类
- Pair-CNN:基于 subject region 和 object region 做分类
- Pair-CNN + BBox
- Pair-CNN + BBox + Union
- Pair-CNN + BBox + Global: 使用整张图片作为 Union-CNN 的输入
- Pair-CNN + BBox + Scene: Union-CNN 更换为 Scene-CNN
- RCNN
- Dual-Glance