感谢谢晓华老师整理的中文文本挖掘入门指南。老师在指南列举了许多文本挖掘常用技术,因为知识点太过零散,所以将各个知识点扩充、归纳、整理如下,希望能够构建一个起一个基本的知识框架。
文本特征表示方法:
在图像和语音领域,可以用像素矩阵、音频频谱序列向量表示图像和语音,属于比较自然地低级数据表示形式。而文字是高度抽象的符号数据,两个词只要字面不同,就难以刻画它们之间的联系,即使是“麦克风”和“话筒”这样的同义词,从字面上也难以看出这两者意思相同(语义鸿沟现象)。
如何有效地表示出语言句子,是文本挖掘的关键前提。
1. 词袋表示(Bag of words)
词袋:这是一个蛮生动的表达。想象一个文本,将所有词放入一个袋子里,忽略其词序、语法、句法等要素,将其仅仅看作是若干个词汇的集合,文本中每个词的出现都是独立的,不依赖于其他词是否出现。
例如有两个简单的文本:
- 小明喜欢看电影
- 小明也喜欢踢足球
基于这两个句子,可以构建出一个词典,key为这个词的索引序号,value为上文出现过的词。
{ 1:“小明”, 2:“喜欢”,3:“电影”,4:“足球”,5:“看”,6:“踢”,7:“也” }
那么,上面两个句子用词袋模型表示成向量就是:
- [1, 1, 1, 0, 1, 0, 0]
- [1, 1, 0, 1, 0, 1, 1]
这种基于词频统计的方法,可以将每段文本映射成一个向量。但如果每段文本不加任何预处理的都这样映射,那么生成的向量势必将会非常庞大,因为向量长度等于字典长度。所以需要一些额外预处理。
TF-IDF
TF-IDF是对上述表示方法的改进。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
下面解释其具体实现。
TF(Term Frequency):词频,即一个词在文本中出现的频率
TF = 某个词在文章中的出现次数 / 文章总词数
IDF(Inverse Document Frequency):逆文档频率,即一个词在所有文本中出现的频率倒数。
IDF = log(语料库的文档总数/包含该词的文档总数+1)
TF-IDF = 词频(TF) * 逆文档频率(IDF)
因此,如果一个词在某文本中出现的越多(TF越大),在其他文本中出现的越少(包含该词的文档总数越少,则IDF越大),则TF-IDF就越大,那么这个词能很好地反映文本的内容。
不管是Count Vector还是TF-IDF Vector,本质都是基于one-hot representation的。
2. 词向量(Word Embedding)表示
词袋表示法,实现简单(还有点粗暴),因此有不少缺点:
- 向量的维度会随着字典长度增大而增大,且一个词要用大量其余的词来表示,为后续运算带来了很大的麻烦
- 任意两个词之间都是孤立的,根本无法表示出在语义层面上词与词之间的相关信息
因此,又提出了词的分布式表示(distributed representation)。Harris 在 1954 年提出的分布假说( distributional hypothesis)为这一设想提供了理论基础:上下文相似的词,其语义也相似。Firth 在 1957 年对分布假说进行了进一步阐述和明确:词的语义由其上下文决定。
这种基于分布假说的词表示方法,可以分成两步:
- 选择一种方式描述上下文
- 选择一种模型刻画某个词与其上下文之间的关系。
除了能够保留词与词之间的关系,通过训练,能将每个词都映射到一个较短的词向量上来。而基于较短的词向量,也能够较容易的分析词之间的关系了。
词的分布式表示可以分为三类:
- 基于矩阵的分布表示
- 基于聚类的分布表示
- 基于神经网络的分布表示,词嵌入( word embedding)
前两种方法就不赘述了,下文仅围绕第三种方法展开。
介绍完历史背景,再让我们看回Word Embedding
Word Embedding 是什么?
如果将word看作文本的最小单元,可以将Word Embedding理解为一种映射,其过程是:将文本空间中的某个word,通过一定的方法,映射或者说嵌入(embedding)到另一个数值向量空间。
one-hot是Word Embedding最简单的实现方式。
基于神经网络语言模型实现的Word Embedding,有以下几种:
- Neural Network Language Model ,NNLM
- Log-Bilinear Language Model, LBL
- Recurrent Neural Network based Language Model,RNNLM
- Collobert 和 Weston 在2008 年提出的 C&W 模型
- Mikolov 等人提出了 CBOW( Continuous Bagof-Words)和 Skip-gram 模型
CBOW(continues bag of words)
本质:通过context来预测word
假设有一个文本 He is a boy。基于one-hot representation 可得到每个词的编码:
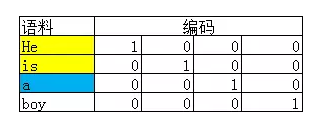
假设选取Context Window为2,那么模型中的一对input和target就是:
- input:He和is的one-hot编码
- target:a的one-hot编码
接着通过一个浅层神经网络来拟合该结果,如下图所示:
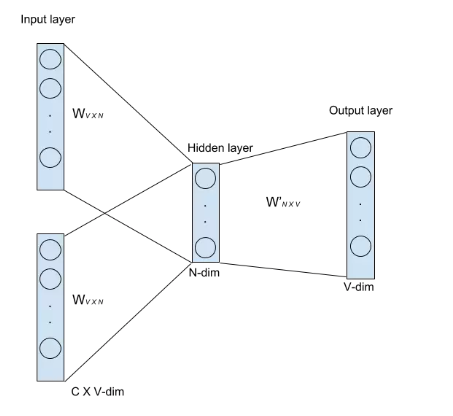
这个训练过程的基本原理为:
输入为C个V维的vector。其中C为上下文窗口的大小,V为原始编码空间的规模。例如,示例中的C=2,V=4.两个vector分别为4维的He和is的one-hot编码形式;
每个input vector分别乘以一个VxN维度的矩阵,得到后的向量各个维度做平均,得到隐藏层的权重。隐藏层乘以一个NxV维度的矩阵,得到1xV的output;
隐藏层的维度设置为理想中压缩后的词向量维度。示例中假设我们想把原始的4维的原始one-hot编码维度压缩到2维,那么N=2;
输出层是一个softmax层,用于组合输出概率。所谓的损失函数,就是这个output和target之间的的差(output的V维向量和input vector的one-hot编码向量的差),该神经网络的目的就是最小化这个loss;
优化结束后,隐藏层的N维向量就可以作为Word-Embedding的结果。
计算output的V维向量和input vector的one-hot编码向量的差,因为词库是相当大的,V通常很大。基于哈夫曼编码的Hierarchical softmax可以筛选掉了一部分不可能的词。