写在前面:
感谢牛客网这个平台,感谢师兄师姐们的经验分享。
除了整理题目,自己也尝试给出个相对完整的回答。
C/C++知识点
介绍一下构造函数、析构函数、函数重载
构造函数:一种特殊的成员函数,它会在每次创建类的新对象时执行
构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void
构造函数可以带有参数。这样在创建对象时就会给对象赋初始值。
如果我们没有定义构造函数,系统会为我们自动定义一个无参的默认构造函数的,默认的构造函数没有任何参数,它不对成员属性做任何操作,如果我们自己定义了构造函数,系统就不会为我们创建默认构造函数了。
析构函数:也是一种特殊的成员函数,它会在每次删除所创建的对象时执行
析构函数的名称与类的名称是完全相同的,只是在前面加了个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源。
函数重载:在同一作用域中声明几个类似的同名函数,常用来处理实现功能类似数据类型不同的问题。
例如,我们可以定义三个不同类型求和的add函数:
1
2
3
4
5
6
7
8
9
10
11int Add(int a, int b) {
return a + b;
}
double Add(double a, double b) {
return a + b;
}
float Add(float a, float b) {
return a + b;
}函数重载需遵循以下规则:
- 函数名称必须相同
- 参数列表必须不同(个数不同、类型不同、参数排列顺序不同等)
- 函数的返回类型可以相同也可以不相同
- 仅仅返回类型不同不足以成为函数的重载
函数重载是一种静态多态。
- C语言不支持函数重载,因为函数名相同的两个函数,在编译之后的函数名也照样相同。
- C++支持函数重载,因为编译之后生成的函数名包括原本函数名、参数表及返回值类型。
堆(heap)和栈(stack)的区别
(这里的堆和数据结构的堆是两回事)
申请方式不同
堆由程序员手动分配
在C中用的是malloc函数:
1
p1 = (char*) malloc (10);
在C++中用的是new函数:
1
p2 = (char*) malloc(10);
栈由系统自动分配
例如,声明在函数中一个局部变量int b; 系统自动在栈中为b开辟空间。
申请效率比较:
- 栈由系统自动分配,速度较快,但是程序员无法控制
- 堆是由new分配内存,一般速度比较慢
结构不同:
栈是一种线性结构
在Windows下,栈是向低地址扩展的数据结构(栈顶地址总是小于等于栈的基地址),是一块连续的内存区域。栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆是一种链式结构
堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
申请后,系统的响应不同:
- 栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
- 堆:操作系统有一个记录空闲内存地址的链表。当系统收到程序的申请时, 会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
如果你在函数上面定义了一个指针变量,然后在这个函数里申请了一块内存让指针指向它。实际上,这个指针的地址是在栈上,但是它所指向的内容却是在堆上面的!
new/delete和malloc/free的区别
malloc和free是标准库函数,需要头文件支持;new和delete是操作符,需要编译器支持,可以重载
1
2
3
4
5
6
7//new的重载
//重载 operator new 的参数个数是可以任意的 , 只需要保证第一个参数为 size_t(代表要申请的内存字节的大小),返回类型为 void * 即可
void * operator new(size_t size) {
cout << "new size:" << size << endl;
void * p = malloc(size);
return p;
}malloc仅仅分配内存空间,free仅仅回收空间,不具备调用构造函数和析构函数功能;
new和delete除了分配回收功能外, 还会调用构造函数和析构函数。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
using namespace std;
class Player{
public:
Player(){
cout << "call Player::ctor\n";
}
~Player(){
cout << "call Player::dtor\n";
}
void Log(){
cout << "i am player\n";
}
};
int main(){
cout << "Initiate by new\n";
Player* p1 = new Player();
p1->Log();
delete p1;
cout << "Initiate by malloc\n";
Player* p2 = (Player*)malloc(sizeof(Player));
p2->Log();
free(p2);
}输出结果为:
1
2
3
4
5
6
7
8
9
10
11Initiate by new
call Player::ctor
i am player
call Player::dtor
Initiate by malloc
i am player使用malloc时需要显式地指出所需内存的尺寸;
使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。
1
2char* str = (char*)malloc(sizeof(char*) * 6);
char* str = new char[6];malloc内存分配成功返回的是void *,需要通过强制类型转换将void *指针转换成需要的类型;
new内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配。因此,new是类型安全的。
malloc函数从堆上动态分配内存;
new操作符从自由存储区(free store)上为对象动态分配内存空间。
自由存储区:凡是通过new操作符进行内存申请,该内存即为自由存储区。自由存储区是否能够是堆,取决于operator new的实现细节。
malloc分配内存失败时返回NULL;在调用malloc动态申请内存块时,要进行返回值的判断。
new内存分配失败时,会抛出bac_alloc异常。
C++语言的优缺点
在C语言的基础上,C++增加下面的内容:
- 类型检查更加严格
- 增加了面向对象机制
- 增加了泛型编程的机制
- 增加了函数重载和运算符重载
- 异常处理机制
- 标准模板库STL
因此,C++有以下优点:
既保持了C语言的简介、高效和接近汇编语言等,又克服了C语言的缺点,其编译系统能检查更多的语法错误
代码可读性好
可重用性好
可移植
提供了标准库STL
面向对象机制。C++既支持面向过程的程序设计,又支持面向对象的程序设计
C++的缺点:
- 相对java来说,没有垃圾回收机制,可能引起内存泄露
- 开发周期长
- 非并行
编译型和解释型语言区别
计算机语言只能理解机器语言,任何高级语言编写的程序,需转换成机器语言(也就是机器码),才能被计算机运行。这种转换分为:
- 编译
- 解释
因此,高级语言分为编译型语言和解释型语言。
编译型语言:
需通过编译器(compiler)将源代码编译成机器码,之后才能执行的语言。一般需经过编译(compile)、链接(linker)这两个步骤。
- 编译是把源代码编译成机器码
- 链接是把各个模块的机器码和依赖库串连起来生成可执行文件。
优点:
编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行
(一次编译,多次运行)
执行速度快。用C/C++编写的程序运行速度比用Java编写的相同程序快30%-70%
缺点:
- 编译之后如果需要修改就需要整个模块重新编译
- 编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件(面向特定平台,因而是平台依赖的)
解释型语言:
解释型语言的程序不需要编译,但是解释性语言在运行程序的时候需要逐行翻译。(运行的时候,将程序翻译成机器语言)
优点:
- 平台独立性:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)
缺点:
- 每次运行的时候都要解释一遍,性能上不如编译型语言
- 占用更多的内存和CPU资源(为了运行解释型语言编写的程序,相关的解释器必须首先运行)
Java是解释型语言,其所谓的编译过程只是将.java文件编程成平台无关的字节码.class文件,并不是向C一样编译成可执行的机器语言。Java类文件不能再计算机上直接执行,它需要被Java虚拟机(JVM)翻译成本地的机器码后才能执行,而java虚拟机的翻译过程则是解释性的。
C可以实现多态吗?怎么实现?
介绍下C++的多态
多态:顾名思义,就是多种形态,方法的行为应取决于调用方法的对象\。
多态分为静态多态和动态多态。
静态多态:在系统编译期间就可以确定程序执行到这里将要执行哪个函数
第一点提到的函数重载,就是静态多态的一种。
动态多态:基于虚函数实现(重写,也称覆盖)。系统编译的时候并不知道程序将要调用哪一个函数,只有在运行到这里的时候才能确定接下来会跳转到哪一个函数的栈帧
在基类声明函数时,在函数前加virtual关键字,则该函数为虚函数。
在子类中,可以对虚函数重新定义(子类中的该函数的函数名,返回值,函数参数个数,参数类型,全都与基类的所声明的虚函数相同,此时才能称为重写,才符合虚函数,否则就是函数的重载)
举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class A {
public:
A(int a = 10)
:_a(a)
{}
virtual void Get() {
cout << "A:: _a=" << _a << endl;
}
public:
int _a;
};
class B : public A {
public:
B(int b = 20)
:_b(b)
{}
void Get() {
cout << "B:: _b=" << _b << endl;
}
public:
int _b;
};
int main() {
A a1;
B b1;
A* ptr1 = &a1; //ptr1是基类指针
ptr1->Get();
ptr1 = &b1; //基类指针可以指向派生类对象中的基类部分
ptr1->Get(); //在派生类的基类部分中,派生类的虚函数取代了基类原来的虚函数
return 0;
}在B类中,对A类的虚函数进行了重写。得到的结果为:
1
2A:: _a=10
B:: _b=20
介绍下C++的虚函数
虚函数的作用是允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类中的同名函数。
虚函数的具体例子可以参考第7点。虚函数的使用需要遵守以下规则:
在基类用virtual声明成员函数为虚函数
在派生类中重新定义此函数,要求函数名、函数类型、函数参数个数和类型全部与基类的虚函数相同。在派生类重新声明该虚函数时,可以加virtual,也可以不加,但习惯上一般在每一层声明该函数时都加virtual,使程序更加清晰。如果在派生类中没有对基类的虚函数重新定义,则派生类简单地继承其直接基类的虚函数。
通过基类指针来访问基类或派生类中的同名函数。程序将根据引用或指针指向的对象类型来选择方法,而不是根据指针类型来选择方法。
调用派生类的同名函数,只要先改变基类指针的指向。如第7点例子中的:
1
ptr1 = &b1;
如果基类中定义的非虚函数会在派生类中被重新定义,并不具备虚函数的功能,不是多态行为。
- 如果用基类指针调用该成员函数,则系统会调用基类部分的成员函数
- 如果用派生类指针调用该成员函数,则系统会调用派生类对象中的成员函数
引用和指针的区别,引用需要释放内存吗?
引用是某块内存的别名;
指针指向一块内存,它的内容是所指内存的地址;
引用只是别名,不占用具体存储空间,只有声明没有定义;
指针是具体变量,需要占用存储空间。
引用在声明时必须初始化为另一变量,例如:
1
2int m = 1;
int &n = m; //n相当于m的别名,对n的任何操作就是对m的操作指针声明和定义可以分开,可以先只声明指针变量而不初始化,等到用时再指向具体变量。
引用一旦初始化之后就不可以再改变;
指针变量可以重新指向别的变量
不存在指向空值的引用;
存在指向空值的指针。
理论上,对于指针的级数没有限制,但是引用只能是一级。
* 为解引用,引用使用时无需解引用,指针使用时需要解引用
在以下情况中,应该使用指针:
- 存在指向空对象的情况
- 需要改变指针的指向
如果指向一个非空对象,且一旦指向对象后不需要改变指向,那么应该使用引用
解释下什么时候会造成栈溢出、堆溢出?
栈溢出:
栈是线程私有的,他的生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口灯信息。
栈溢出,即创建的栈帧超过了栈的深度。有可能是由函数调用层次太深造成。(因为系统要在栈中不断保存函数调用时的现场和产生的变量)
堆溢出:
有以下两种情况:
- 内存泄露(memory leak)
- 向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete)
- 内存泄漏的堆积,会最终消耗尽系统所有的内存
- 内存溢出(out of memory)
- 指程序在申请内存时,没有足够的内存空间供其使用
- 内存溢出的常见原因有以下几种:
- .内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
- 存在死循环
- 程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存(new完之后不delete)
编译和链接的过程
C++语言程序转换成机器语言需要经历以下过程:
源程序->预处理->编译和优化->生成目标文件->链接->可执行文件
*.c/*.cpp-> *.i-> *.S -> *.o->链接-> *.exe
预处理:
- 宏的替换(#define, #ifndef)
- 删除注释
编译和优化:
词法分析 – 识别单词,确认词类
比如int i:知道int是一个类型,i是一个关键字以及判断i的名字是否合法
语法分析 – 识别短语和句型的语法属性
语义分析 – 确认单词、短语和句型的语义特征
代码优化 – 修辞、文本编辑
代码生成 – 生成译文
内联函数的替换就发生在这一阶段
编译形成汇编文件,里面存放的都是汇编代码(生成汇编代码)
生成目标文件:
汇编阶段,使用汇编器从汇编代码生成目标代码
编译器把一个cpp编译为目标文件(机器指令)的时候,除了要在目标文件里写入cpp里包含的数据和代码,还要至少提供3个表:未解决符号表,导出符号表和地址重定向表。
- 未解决符号表:提供了所有在该编译单元里引用但是定义并不在本编译单元里的符号及其出现的地址
- 导出符号表:提供了本编译单元具有定义,并且愿意提供给其他编译单元使用的符号及其地址
- 地址重定向表:提供了本编译单元所有对自身地址的引用的记录。
链接:
由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要经链接程序的处理方能得以解决。
可执行文件:
.out或.exe或其他格式
静态链接和动态链接
为什么要进行链接?
- 在我们的实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件。
- 一个源文件可能要调用另一个源文件中定义的函数,但是每个源文件都是独立编译的,即每个*.c文件会形成一个*.o文件
- 为了满足依赖关系,需要将这些源文件产生的目标文件进行链接,从而形成一个可以执行的程序
静态链接的原理
根据源文件中包含的头文件和程序中使用到的库函数,如stdio.h中定义的printf()函数,在libc.a中找到目标文件printf.o(这里暂且不考虑printf()函数的依赖关系),然后将这个目标文件和我们hello.o这个文件进行链接形成我们的可执行文件。
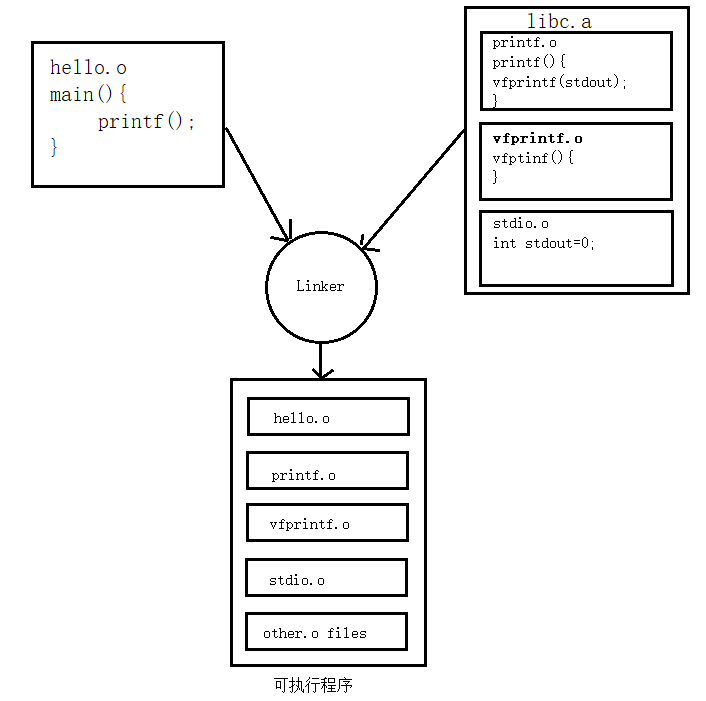
这里,我们引用了静态库中的printf()函数,那么链接器就会把库中包含printf()函数的那个目标文件链接进来。如果很多函数都放在一个目标文件中,很可能很多没用的函数都被一起链接进了输出结果中。
静态链接的缺点:
浪费空间
因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,如多个程序中都调用了printf()函数,则这多个程序中都含有printf.o,所以同一个目标文件都在内存存在多个副本。
更新困难
每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序
静态链接的优点:
在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快
动态链接的原理
动态链接出现的原因就是为了解决静态链接中提到的两个问题,一是空间浪费,二是更新困难。
基本思想:是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
动态链接的过程:假设现在有两个程序program1.o和program2.o,这两者共用同一个库lib.o,假设首先运行程序program1,系统首先加载program1.o,当系统发现program1.o中用到了lib.o,即program1.o依赖于lib.o,那么系统接着加载lib.o,如果program1.o和lib.o还依赖于其他目标文件,则依次全部加载到内存中。当program2运行时,同样的加载program2.o,然后发现program2.o依赖于lib.o,但是此时lib.o已经存在于内存中,这个时候就不再进行重新加载,而是将内存中已经存在的lib.o映射到program2的虚拟地址空间中,从而进行链接(这个链接过程和静态链接类似)形成可执行程序。
动态链接的优点:
解决空间浪费
多个程序都依赖同一个库时,该库不会像静态链接那样在内存中存在多份副本,而是这多个程序在执行时共享同一份副本
解决更新困难
更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。
当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。
动态链接的缺点:
把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失
什么是静态链接库?什么是动态链接库?
由【链接阶段】如何处理库,链接成可执行程序,分成:
- 动态链接
- 静态链接
静态链接库的特点:
- 一个静态库可以简单看成是一组目标文件(.o/.obj文件)的集合,即很多目标文件经过压缩打包后形成的一个文件
- 静态库对函数库的链接是放在编译时期完成的
- 静态链接时,使用静态连接库
- 静态链接库是将全部指令都包含入调用程序生成的EXE文件中
动态链接库(Dynamaic Link Library, DLL)的特点:
- 动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入
- 不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例
- 动态链接库的使用需要库的开发者提供生成的.lib文件和.dll文件。或者只提供dll文件。
- DLL文件与EXE文件独立,只要输出接口不变(即名称、参数、返回值类型和调用约定不变),更换DLL文件不会对EXE文件造成任何影响,因而极大地提高了可维护性和可扩展性
- DLL中虽然包含了可执行代码,却不能单独执行,应有Windows应用程序直接或间接调用
解释下函数指针
函数指针,即指向函数的指针,可以灵活地调用不同函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
int get_max(int i,int j) {
return i>j?i:j;
}
int get_min(int i,int j) {
return i>j?j:i;
}
int compare(int i,int j,int flag) {
int ret;
//这里定义了一个函数指针,就可以根据传入的flag,灵活地决定其是指向求大数或求小数的函数
//便于方便灵活地调用各类函数
int (*p)(int,int);
if(flag == GET_MAX)
p = get_max; //get_max不用带括号,也不用带参数
else
p = get_min;
ret = p(i,j);
// 或者,ret = (*p)(i,j);
return ret;
}
int main() {
int i = 5,j = 10,ret;
ret = compare(i,j,GET_MAX);
printf("The MAX is %d\n",ret);
ret = compare(i,j,GET_MIN);
printf("The MIN is %d\n",ret);
return 0 ;
}说一下常用设计模式:单例、工厂、观察者、适配器
- C和C++的区别
面向过程和面向对象的区别
面向过程:
- 分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现
面向对象:
- 把构成问题的事务分解成各个对象
- 面向对象就是高度实物抽象化
以走五子棋为例,面向过程的设计思路是:
- 开始游戏
- 黑棋先走
- 绘制画面
- 判断输赢
- 白棋再走
- 绘制画面
- 判断输赢
- 返回步骤2
- 输出结果
面向对象的设计思路是:
- 黑白双方,同一个类
- 棋盘系统,负责绘制画面
- 规则系统,负责判断输赢
面向对象的三大特性:
- 封装:把属性和方法都封装在一个类中;隐藏内部实现细节(维护了内部代码的安全),提供外部接口;不同的成员具有不同的访问权限(维护了数据的安全),因此封装维护了代码的安全性
- 继承:提供了代码的重用能力。例如,派生类继承基类时,与基类相同的特性就不用再定义一次了,只需修改不一样的特性
- 多态:对于不同的实例,某个操作可能会有不同的行为(某个操作,即函数名相同)。具体可见第7点。
C和C++动态分配的区别
- C语言中采用malloc(),calloc(),realloc()来进行内存分配,而释放内存的函数为free()
- C++语言中用new和delete来动态申请和释放内存
C++内存分配的方式
C语言的变量分为:全局变量、本地变量、静态变量、寄存器变量。每种变量都有不同的分配方式。
内存在逻辑上分成3个部份:代码区,静态数据区和动态数据区。动态数据区一般就是“堆栈”。
全局变量和静态变量分配在静态数据区,本地变量分配在动态数据区,即堆栈中。
调用函数过程中,函数的形参以从右到左的次序压入堆栈,然后压入函数的返回地址,接着跳转到函数地址接着执行,然后栈顶(ESP)减去一个数,为本地变量分配内存空间,并初始化本地变量的内存空间。函数返回前要恢复堆栈,先回收本地变量占用的内存,然后取出返回地址,回收先前压入参数占用的内存,继续执行调用者的代码。
看到另一篇博客,将由C/C++编译的程序占用的内存分为以下几个部分:
- 栈区(stack)
- 堆区(heap)
- 全局区(静态区)(static):存放全局变量和静态变量
- 文字常量区:存放常量字符串
- 程序代码区:存放函数体的二进制代码
一个很详细的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13int a = 0; 全局初始化区
char *p1; 全局未初始化区
void main() {
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //"123456"在常量区,p3在栈上。
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); //"123456"放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
int *p[10] 和 int (*p)[10]的区别
- int *p[10] :指针数组,即一个大小为10的数组,数组中每一个元素都为int*型
- int (*p)[10]:p为指向大小为10的int数组的指针
int* f(int i, int j) 和 int (*p)(int i, int j)的区别
- int* f(int i, int j):返回值是指针的函数(指针函数)
- int (*p)(int i, int j):一个指向函数的指针
使用 delete 和使用 delete[] 的区别
对于简单类型(int / char/ long / int* / struct),使用new分配后,不管是使用delete还是delete[]空间释放空间均可。因为在分配简单型内存时,内存大小已经确定,系统可以记忆并且进行管理,在析构时,系统并不会调用析构函数。
1
2
3
4int *a = new int[10];
delete a;
delete [] a;
//两种方式均可针对类,delete只释放了指针指向的第一个对象的空间,而delete[]能释放指针指向的全部内存空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
using namespace std;
class Babe {
public:
Babe() {
cout << \"Create a Babe to talk with me\" << endl;
}
~Babe() {
cout << \"Babe don\'t go away,listen to me\" << endl;
}
};
int main() {
Babe* pbabe = new Babe[3];
delete pbabe;
pbabe = new Babe[3];
delete pbabe[];
return 0;
}运行的结果是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Create a babe to talk with me
Create a babe to talk with me
Create a babe to talk with me
Babe don\'t go away,listen to me
Create a babe to talk with me
Create a babe to talk with me
Create a babe to talk with me
Babe don\'t go away,listen to me
Babe don\'t go away,listen to me
Babe don\'t go away,listen to me可以看出,使用delete时,析构函数仅被调用一次,而使用delete[],析构函数被调用了三次。
因此,为了避免内存泄露,应该使用delete[]
C++怎么调用C的函数?
函数被C++编译后在符号库中的名字与C语言的不同,此外,C++还支持类成员变量等。那么怎么实现C++与C的混合编程。
如果C++调用一个C语言编写的.DLL时,当包括.DLL的头文件或声明接口函数时,应加extern “C” { }
加上extern “C”后,会指示编译器这部分代码按C语言的进行编译和链接,而不是C++的。
假设同一个目录下,假如main.cpp需要调用calc.h中的函数(calc.c是c代码),应该在calc.h中的每个函数最前面添加:extern “C”
1
2
3
4
5extern "C" {
void fun1(int arg1);
void fun2(int arg1, int arg2);
void fun3(int arg1, int arg2, int arg3);
}若不确定当前编译环境是C还是C++,可以这样:
1
2
3
4
5
6
7
8
9
10
11
extern "C" {
void fun1(int arg1);
void fun2(int arg1, int arg2);
void fun3(int arg1, int arg2, int arg3);
}或者:
1
2
3extern "C" {
}
main函数的参数问题
main函数是C语言约定的入口函数,main函数有两种常见的写法
int main(void) 或 int main()
int main(int argc, char *argv[], char *envp[]) 或 int main(int argc, char **argv, char **envp) 或 int main(int argc, char argv[][], char envp[][])
argc:标识参数个数
argv:指针数组,为参数列表
argv[]数组的第一个元素存放编译的C文件的路径;argv[1]指向执行程序名后的第一个字符串 ,表示真正传入的第一个参数; argv[]数组最后一个元素(argv[argc])恒存放一个空指针,作为argv数组的结束标志
(argv[i]存放的是一个char数组)

envp:环境参数
main函数可以从命令行获取参数
C/C++ 中从来没有定义过void main( ) 。C++ 之父 Bjarne Stroustrup 在他的主页上的 FAQ 中明确地写着 “The definition void main( ) { /* … */ } is not and never has been C++, nor has it even been C.”
使用main函数的带参版本的时,最常用的就是:int main(int argc , char* argv[]);
main函数如何执行
main函数的返回值
- main 函数的返回值类型应该定义为 int 类型,C 和 C++ 标准中都是这样规定的。
- main函数返回0,代表函数正常退出,执行成功;返回非0,代表函数出先异常,执行失败。
main函数运行前的工作
- 设置栈指针
- 初始化static静态和global全局变量,即data段的内容
- 将未初始化部分的赋初值:数值型short,int,long等为0,bool为FALSE,指针为NULL等等,即.bss段的内容
- 运行全局构造器,类似c++中全局构造函数
- 将main函数的参数(argc,argv)等传递给main函数,然后才真正运行main函数
- 通过关键字attribute,让一个函数在主函数之前运行,进行一些数据初始化、模块加载验证等
main函数之后执行的函数
全局对象的析构函数会在main函数之后执行
用atexit注册的函数也会在main之后执行
atexit 函数可以“注册”一个函数,使这个函数将在main函数正常终止时被调用,当程序异常终止时,通过它注册的函数并不会被调用。每个被调用的函数不接受任何参数,并且返回类型是 void。通过atexit可以注册回调清理函数,可以在这些函数中加入一些清理工作,比如内存释放、关闭打开的文件、关闭socket描述符、释放锁等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
void fn0( void ), fn1( void ), fn2( void ), fn3( void ), fn4( void );
int main( void ) {
//注意使用atexit注册的函数的执行顺序:先注册的后执行
atexit( fn0 );
atexit( fn1 );
atexit( fn2 );
atexit( fn3 );
atexit( fn4 );
printf( "This is executed first.\n" );
printf("main will quit now!\n");
return 0;
}
void fn0() {
printf( "first register ,last call\n" );
}
void fn1(){
printf( "next.\n" );
}
void fn2() {
printf( "executed " );
}
void fn3() {
printf( "is " );
}
void fn4() {
printf( "This " );
}输出结果应为:
This is executed first.
main will quit now!
This is executed next.
first register ,last call
回调函数
一个函数指针作为参数传递给其他函数,当这个指针被用来调用其所指向的函数,这就是回调函数。
回调函数可以把调用者与被调用者分开。调用者不关心谁是被调用者,所有它需知道的,只是存在一个具有某种特定原型、某些限制条件(如返回值为int)的被调用函数。
根据所传入的参数不同而调用不同的回调函数。比如,我们为几个不同的设备分别写了不同的显示函数:void TVshow(); void ComputerShow(); void NoteBookShow()…等等。这是我们想用一个统一的显示函数,我们这时就可以用回调函数void show(void (*ptr)());
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int add_ret() ;
int add(int a , int b , int (*add_value)(int, int)) {
//由函数指针,知道参数为两个int,返回值为int
return (*add_value)(a,b);
}
int main(void) {
int sum = add(3,4,add_ret);
printf("sum:%d\n",sum);
return 0 ;
}
int add_ret(int a , int b) {
return a+b ;
}变量声明和定义的区别?
声明:向程序表明变量的类型和名字,并不分配内存空间。
通过extern声明变量,告诉变量在其他地方定义了,链接阶段需要从其他模块寻找外部函数和变量
1
2extern int i; //声明,不是定义
int i; //声明,也是定义,未初始化除非有extern关键字,否则都是变量的定义
extern只能修饰全局变量
定义:为变量分配存储空间,还可以为变量指定初始值
如果声明有初始化,应该视为定义,即使前面加了extern。并且,只有当extern声明位于函数外部时,才可以被初始化
1
extern double pi=3.141592654; //定义
相同变量可以在多处声明(外部变量extern),但只能在一处定义
友元函数
从一定程度上讲,友元是对数据隐藏和封装的破坏,但是为了数据共享,提高程序的效率和可读性,很多情况下这种小的破坏是必要的。
- 类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。
- 尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
- 友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类,在这种情况下,整个类及其所有成员都是友元。友元还可以是其他类的公有成员函数。
- 声明可以放在类的私有部分,也可放在公有部分。
- 友元关系在类之间不能传递,友元函数也不能被继承
- 友元函数没有this指针
- 友元函数可以访问类中的私有成员和其他数据,但是访问不可直接使用数据成员,需要通过对对象进行引用。友元函数的参数具体有三种情况:
- 访问非static成员时,需要对象做参数
- 访问static成员或全局变量时,则不需要对象做参数
- 如果做参数的对象是全局对象,则不需要对象做参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
using namespace std;
class Box {
double width;
public:
friend void printWidth( Box &box );
void setWidth( double wid );
};
// 成员函数定义
void Box::setWidth( double wid ) {
width = wid;
}
// 请注意:printWidth() 不是任何类的成员函数
void printWidth( Box &box ) {
/* 因为 printWidth() 是 Box 的友元,它可以直接访问该类的任何成员 */
cout << "Width of box : " << box.width <<endl;
}
// 程序的主函数
int main( ) {
Box box;
// 使用成员函数设置宽度
box.setWidth(10.0);
// 使用友元函数输出宽度
printWidth( box );
return 0;
}运算符重载
重载运算符是带有特殊名称的函数,函数名是由关键字 operator 和其后要重载的运算符符号构成的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
using namespace std;
class Box
{
public:
double getVolume(void) {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
// 重载 + 运算符,用于把两个 Box 对象相加
Box operator+(const Box& b) {
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // 长度
double breadth; // 宽度
double height; // 高度
};
// 程序的主函数
int main( ) {
Box Box1; // 声明 Box1,类型为 Box
Box Box2; // 声明 Box2,类型为 Box
Box Box3; // 声明 Box3,类型为 Box
double volume = 0.0; // 把体积存储在该变量中
// Box1 详述
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// Box2 详述
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// Box1 的体积
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// Box2 的体积
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// 把两个对象相加,得到 Box3
Box3 = Box1 + Box2;
// Box3 的体积
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}extern的用法
- extern用在变量或函数的声明前,用来说明“此变量/函数是在别处定义的,要在此处引用”。
- 使用extern和包含头文件来引用函数的区别:
- extern的使用方法是直接了当的,想引用哪个函数就用extern声明哪个函数
- 使用extern会加速程序的编译(确切地说是预处理)的过程,节省时间
- 在C++中调用C库函数,就需要在C++程序中用extern “C”声明要引用的函数
inline函数
零值比较
- bool类型:if(flag)
- int类型:if(flag == 0)
- 指针类型:if(flag == null)
- float类型:if((flag >= -0.000001) && (flag <= 0. 000001))
结构体内存对齐问题
- 偏移量 = 结构体成员的地址 - 结构体的首地址,偏移量必须是当前成员大小的整数倍
- 结构体大小必须是最宽成员大小的整数倍
public/protected/private的区别?
- public的变量和函数在类的内部外部都可以访问
- protected的变量和函数只能在类的内部和其派生类中访问
- private修饰的元素只能在类内访问
构造函数能否为虚函数,析构函数呢?
构造函数:
构造函数不能定义为虚函数。
构造函数为虚函数,本身就是没有意义的。C++之父 Bjarne Stroustrup 在《The C++ Programming Language》里是这样说的:
To construct an object, a constructor needs the exact type of the object it is to create. Consequently, a constructor cannot be virtual. Furthermore, a constructor is not quite an ordinary function, In particular, it interacts with memory management in ways ordinary member functions don’t. Consequently, you cannot have a pointer to a constructor.
构造一个对象的时候,必须知道对象的实际类型,而虚函数行为是在运行期间确定实际类型的。
虚函数的执行依赖于虚函数表。而在构造对象期间,虚函数指针(vptr)还没有被初始化,将无法进行。
析构函数:
析构函数可以为虚函数,并且一般情况下基类析构函数要定义为虚函数。
只有在基类析构函数定义为虚函数时,调用操作符delete销毁指向对象的基类指针时,才能准确调用派生类的析构函数(从该级向上按序调用虚函数),才能准确销毁数据。
例如,假设Employee是基类,Singer是派生类,并添加新的成员。
1
2
3Employ *pe = new Singer;
…
delete pe;如果基类的析构函数不是虚函数,此时使用的静态联编,方法是通过指针类型(而不是指针指向的对象)来选择的。因此,如果析构函数不虚,只调用指针类型的析构函数,即delete语句将调用Employee的析构函数,释放Singer对象中Employee部分指向的内存,但不会释放新的类成员指向的内存。
使用虚构函数可以确保正确的析构函数序列被调用。
因此,即使基类不需要显式析构函数提供服务,也不应依赖于默认构造函数,而应提供虚析构函数,即使它不执行任何操作。
1
virtual ~Employee(){}
析构函数可以是纯虚函数,含有纯虚函数的类是抽象类,此时不能被实例化。但派生类中可以根据自身需求重新改写基类中的纯虚函数。
虚函数与纯虚函数
虚函数:参考第8点
纯虚函数
包含纯虚函数的类,被称为“抽象类”。抽象类不能生成对象
纯虚函数的格式为
1
2
3
4class <类名> {
virtual <类型><函数名>(形参表) = 0; //纯虚函数
...
}纯虚函数仅提供一个接口,不提供具体实现,它的实现留给该基类的派生类去做
如何理解纯虚函数
在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出猴子、犀牛等子类,但动物本身生成对象明显不合理。为了解决上述问题,引入了纯虚函数的概念。
构造函数调用顺序,析构函数呢?
- 调用所有虚基类的构造函数,顺序为从左到右,从最深到最浅
- 基类的构造函数:如果有多个基类,先调用纵向上最上层基类构造函数,如果横向继承了多个类,调用顺序为派生表从左到右顺序。
- 如果该对象需要虚函数指针(vptr),则该指针会被设置从而指向对应的虚函数表(vtbl)。
- 成员类对象的构造函数:如果类的变量中包含其他类(类的组合),需要在调用本类构造函数前先调用成员类对象的构造函数,调用顺序遵照在类中被声明的顺序。
- 派生类的构造函数。
- 析构函数与之相反。
拷贝构造函数
拷贝构造函数分为两种:深拷贝构造函数和浅拷贝构造函数
浅拷贝构造函数
浅拷贝函数只是将在类成员间进行简单赋值
默认拷贝构造函数执行的是浅拷贝构造
一旦对象存在了动态成员,那么浅拷贝就会出问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
using namespace std;
class Rect {
public:
Rect() {
p=new int(100);
}
~Rect() {
assert(p!=NULL);
delete p;
}
private:
int width;
int height;
int *p;
};
int main() {
Rect rect1;
Rect rect2(rect1);
return 0;
}这样子的代码会运行错误,因为在进行对象复制时,对于动态分配的内容没有进行正确的操作。
浅拷贝只是将成员的值进行赋值,即rect1.p = rect2.p,这两个指针指向了堆里的同一个空间。在销毁对象时,两个对象的析构函数将对同一个内存空间释放两次,这就是错误出现的原因。
深拷贝构造函数
对于对象中动态成员,应该重新动态分配空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
using namespace std;
class Rect {
public:
Rect() {
p=new int(100);
}
Rect(const Rect& r) {
width=r.width;
height=r.height;
p=new int(100);
*p=*(r.p);
}
~Rect() {
assert(p!=NULL);
delete p;
}
private:
int width;
int height;
int *p;
};
int main() {
Rect rect1;
Rect rect2(rect1);
return 0;
}此时,rect1的p和rect2的p各自指向一段内存空间,空间里具有相同的内容。
覆盖、重载和隐藏的区别?
- 覆盖是派生类中重新定义的函数,其函数名、参数列表(个数、类型和顺序)、返回值类型和父类完全相同,只有函数体有区别。派生类虽然继承了基类的同名函数,但用派生类对象调用该函数时会根据对象类型调用相应的函数。覆盖只能发生在类的成员函数中。
- 隐藏是指派生类函数屏蔽了与其同名的函数,这里仅要求基类和派生类函数同名即可。其他状态同覆盖。可以说隐藏比覆盖涵盖的范围更宽泛,毕竟参数不加限定。
- 重载是具有相同函数名但参数列表不同(个数、类型或顺序)的两个函数(不关心返回值),当调用函数时根据传递的参数列表来确定具体调用哪个函数。重载可以是同一个类的成员函数也可以是类外函数。
this指针
- this指针是类的指针,指向对象的首地址
- this指针只能在成员函数中使用,在全局函数、静态成员函数中都不能用this
- this指针只有在成员函数中才有定义,且存储位置会因编译器不同有不同存储位置
数据结构
- 介绍一下排序算法,并分析时间复杂度、空间复杂度及稳定性
- 二叉搜索树的特性
- 怎么查到第k个大的数
- 单向链表的倒序输出
- 两个链表找第一个交叉节点
- 数组、链表、二叉树、哈希的查找复杂度
Linux语句
- Linux查找目录下txt文件
- 删除目录下txt文件
算法
- 输入1、2、3,输出排列组合
计算机网络
http连接过程
cookie和session的区别
- cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案
- cookie数据存放在客户的浏览器上,session数据放在服务器上
- Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
- 应用场景
- 在我们登录网站时,第一次登录需要输入用户名密码,第二次再打开该网站就直接登录了。这个时候用到的一个机制就是cookie
- session一个场景是购物车,添加了商品之后客户端处可以知道添加了哪些商品,而服务器端如何判别呢,所以也需要存储一些信息就用到了session
- session:
- 服务器存在一种用来存放用户数据的类HashTable结构
- 每个用户访问服务器都会建立一个session,用户与服务器建立连接的同时,服务器会自动为其分配一个SessionId,SessionId存储在cookie中。当用户再次访问服务器时,浏览器会将用户的SessionId自动附加在HTTP头信息中,服务器就能识别当前用户的身份
- session会在一定时间内保存在服务器上。当访问增多,会影响服务器的性能
- 只有ASCII字符串可以存储在cookie中,session可以访问任何类型的数据,包括但不限于字符串、Integer、List、Map等。
TCP的粘包
- 发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才一起发送。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。
- 接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据
百度搜索的过程
http返回码
http请求方法
- GET:获取资源
- POST:传输实体文本
- HEAD:获得报文首部
- PUT:传输文件
- DELETE:删除文件
- OPTIONS:询问支持的方法
- TRACE:追踪路径
- CONNECT:要去用隧道协议连接代理
http和https的区别
HTTP协议是超文本传输协议,以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
HTTPS协议是安全套接字层超文本传输协议,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443
客户端在使用HTTPS方式与Web服务器通信时的步骤:
(1)客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
(2)Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
(3)客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
(4)客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加 密,并传送给网站。
(5)Web服务器利用自己的私钥解密出会话密钥。
(6)Web服务器利用会话密钥加密与客户端之间的通信。

操作系统
什么是死锁?产生的条件是什么?
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去
死锁的发生必须满足以下四个条件:
- 互斥条件:一个资源每次只能被一个进程使用
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系
进程间的通信方式
管道(pipe):一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用
(进程的亲缘关系,通常指父子进程关系)
有名管道(named pipe):也是半双工,但允许无亲缘关系进程间的通信
消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题
信号量:不能传递复杂信息,只能用来同步(控制多个进程对共享资源的访问)
共享内存:能够容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要考虑读写问题。共享内存是最快的进程间通信方式。
套接字(socket):可用于不同机器间的进程通信
线程的资源分配:
线程共享的进程环境包括:
- 进程代码段
- 进程的公有资源
- 进程打开的文件描述符
- 消息队列
- 信号的处理器
- 进程的当前目录
- 进程用户ID
- 进程组ID
- 堆
线程独占资源包括:
- 线程ID(TCB)
- 寄存器组的值
- 栈
- 线程的优先级
MySQL
MySQL是关系型数据库,所谓的“关系型”可以理解成“表格”的概念
主键:主键是唯一的。一个数据表中只能包含一个主键,可以使用主键来查询数据
外键:用于关联两个表
创建MySQL数据表的语句(CREATE):
1
CREATE TABLE table_name(column_name column_type);
例如:创建数据表runoob_tbl:
1
2
3
4
5
6
7CREATE TABLE IF NOT EXISTS 'runoob_tbl'(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)注释:
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
删除MySQL数据表的语句(DROP):
1
DROP TABLE table_name;
例如:删除数据表runoob_tbl:
1
DROP TABLE runoob_tbl;
插入数据的语句(INSERT):
1
2
3INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );例如:
1
2
3
4
5
6
7
8
9INSERT INTO runoob_tbl
(runoob_title, runoob_author, submission_date)
VALUES
("学习 PHP", "菜鸟教程", NOW());
INSERT INTO runoob_tbl
(runoob_title, runoob_author, submission_date)
VALUES
("JAVA 教程", "RUNOOB.COM", '2016-05-06');注释:
- 我们并没有提供 runoob_id 的数据,因为该字段我们在创建表的时候已经设置它为 AUTO_INCREMENT(自动增加) 属性。
- NOW() 是一个 MySQL 函数,该函数返回日期和时间。
查询数据的语句(SELECT):
1
2
3
4SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]注释:
查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
使用 * 号时,会返回满足条件的记录的所有字段数据。(返回完整的一行)。例如,如果要获取runoob_tbl 的所有记录:
1
select * from runoob_tbl;
使用 WHERE 语句来包含任何条件;
在WHERE子句中,可以使用AND或者OR指定一个或多个条件。
1
[WHERE condition1 [AND [OR]] condition2.....
使用 LIMIT 属性来设定返回的记录数。
通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
更新数据的语句(UPDATE):
1
2UPDATE table_name SET field1=new-value1, field2=new-value2
[WHERE Clause]例如,更新数据表中 runoob_id 为 3 的 runoob_title 字段值:
1
UPDATE runoob_tbl SET runoob_title='学习 C++' WHERE runoob_id=3;
删除记录的语句(DELETE):
1
DELETE FROM table_name [WHERE Clause]
注意:
- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除。
举个例子,删除 runoob_tbl 表中 runoob_id 为3 的记录:
1
DELETE FROM runoob_tbl WHERE runoob_id=3;
LIKE子句:
1
2
3SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'例如,从runoob_tbl 表中获取 runoob_author 字段中以 COM 为结尾的的所有记录:
1
SELECT * from runoob_tbl WHERE runoob_author LIKE '%COM';
注释:
- 可以将LIKE视作类似 = 的操作符
- LIKE 通常与 % 一同使用, % 字符表示任意字符
UNION操作符:
1
2
3
4
5
6
7SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions];注释:
- DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据。
MySQL排序(ORDER BY):
1
2SELECT field1, field2,...fieldN table_name1, table_name2...
ORDER BY field1, [field2...] [ASC [DESC]]注释:
- 可以设定多个字段来排序
- 可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列
例如,将runoob_tbl表中的记录按照时间升序排序:
1
SELECT * from runoob_tbl ORDER BY submission_date ASC;
GROUP BY语句:
1
2
3
4SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;例如,已知有数据表employee_tbl:
1
2
3
4
5
6
7
8
9
10+----+--------+---------------------+--------+
| id | name | date | singin |
+----+--------+---------------------+--------+
| 1 | 小明 | 2016-04-22 15:25:33 | 1 |
| 2 | 小王 | 2016-04-20 15:25:47 | 3 |
| 3 | 小丽 | 2016-04-19 15:26:02 | 2 |
| 4 | 小王 | 2016-04-07 15:26:14 | 4 |
| 5 | 小明 | 2016-04-11 15:26:40 | 4 |
| 6 | 小明 | 2016-04-04 15:26:54 | 2 |
+----+--------+---------------------+--------+使用 GROUP BY 语句 将数据表按名字进行分组,并统计每个人有多少条记录:
1
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
注释:
在分组的基础上,可以使用 COUNT, SUM, AVG,等函数
使用WITH GROUP,实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
例如,将以上的数据表按名字进行分组,再统计每个人登录的次数:
1
2
3
4SELECT name, SUM(singin) as singin_count
FROM employee_tbl
GROUP BY name
WITH ROLLUP;
MySQL连接(JOIN):
JOIN按照功能,分为三类:
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录
例如,已知有数据表tcount_tbl和数据表runoob_tbl:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17+---------------+--------------+
| runoob_author | runoob_count |
+---------------+--------------+
| 菜鸟教程 | 10 |
| RUNOOB.COM | 20 |
| Google | 22 |
+---------------+--------------+
+-----------+---------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+---------------+---------------+-----------------+
| 1 | 学习 PHP | 菜鸟教程 | 2017-04-12 |
| 2 | 学习 MySQL | 菜鸟教程 | 2017-04-12 |
| 3 | 学习 Java | RUNOOB.COM | 2015-05-01 |
| 4 | 学习 Python | RUNOOB.COM | 2016-03-06 |
| 5 | 学习 C | FK | 2017-04-05 |
+-----------+---------------+---------------+-----------------+使用INNER JOIN连接以上两张表来读取runoob_tbl表中所有runoob_author字段在tcount_tbl表对应的runoob_count字段值:
1
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
以上 INNER JOIN语句也可以用WHERE字句替换:
1
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a, tcount_tbl b WHERE a.runoob_author = b.runoob_author;
使用LEFT JOIN连接以上两张表来读取runoob_tbl表中所有runoob_author字段在tcount_tbl表对应的runoob_count字段值,并显示runoob_id、runoob_author、runoob_count:
1
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
注释:
该语句会读取左边的数据表 runoob_tbl 的所有选取的字段数据,即便在右侧表 tcount_tbl中 没有对应的 runoob_author 字段值。因此结果为:
1
2
3
4
5
6
7
8
9+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
| 5 | FK | NULL |
+-------------+-----------------+----------------+
同理,使用RIGHT JOIN时:
1
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a RIGHT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
结果为:
1
2
3
4
5
6
7
8
9+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
| NULL | NULL | 22 |
+-------------+-----------------+----------------+
数据库
数据库保护(数据库控制)的四种方式:
- 完全性控制
- 完整性控制
- 并发性控制
- 数据恢复
数据库索引的作用及优缺点
索引的原理大致可以概括为空间换时间。数据库在未添加索引的时候,进行查询默认进行的是全表搜索,也就是有多少条记录就会进行多少次查询。假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,最坏时间复杂度就是O(n),这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用。因此引入了索引。
一条索引记录中包含的基本信息包括:键值+逻辑指针(指向数据页或者另一索引页)
优点:
- 数据库索引可以加快数据的查询速度
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义
缺点:
索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,增删改数据都会改变B树各节点中的索引数据内容,因此数据的维护速度变慢
创建索引和维护索引需耗费时间
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大
对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
数据结构:基于B树或者B+树。
聚集索引
非聚集索引
聚集索引 VS 非聚集索引
通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据。
- 聚集索引:在索引表上逻辑相邻的记录,在物理位置上也相邻
- 非聚集索引:索引的逻辑顺序与磁盘上记录的物理存储顺序不同
一个很形象的例子来说明聚集索引和非聚集索引的区别。
- 聚集索引类似于我们根据汉字拼音在汉语字典中查询某个字。“安”的拼音是“an”,而按照拼音排序,汉语字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。在拼音表中,“安”的下一个字“按”的拼音也是“an”,在字典中的顺序也排在“安”的下一个字。这种逻辑顺序与物理顺序一致的索引,为聚集索引
- 非聚集索引类似于我们根据偏旁部首在汉语字典中查询某个字。比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方。这种索引方式需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。
数据库事务的特性
数据库事物隔离级别
- 读未提及(Read Uncommitted)
- 允许脏读,其隔离级别是最低的。
- 脏读:一个事务处理过程里读取了另一个未提交的事务中的数据
- 读已提交(Read Committed)
- 不会出现脏读的情况
- 不同执行的时候只能获取到已经提交的数据
- 可重复读(Repeated Read)
- 保证在事务处理过程中,多次读取同一个数据时,该数据的值和事务开始时刻是一致的
- 串行读(Serializable)
- 完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
事务隔离级别 脏读 不可重复读 幻读 读未提及(Read Uncommitted) 允许 允许 允许 读已提交(Read Committed) 禁止 允许 允许 可重复读(Repeated Read) 禁止 禁止 允许 串行读(Serializable) 禁止 禁止 禁止 - 读未提及(Read Uncommitted)